赵 霞,李 朝,付 锐,葛振振,王 畅
(长安大学汽车学院,西安 710064)
随着人工智能技术、传感器技术、互联网技术、大数据以及5G网络的发展,自动驾驶在近年来取得了重大突破[1]。然而受交通立法、伦理、现有道路状况以及更高精深技术的限制,完全自动驾驶在短时间内很难实现,这就意味着以人为中心的人机共驾模式将继续持续很长一段时间[2]。随着人机共驾策略的深入发展,研究人员逐渐意识到驾驶人状态对于人机共驾系统决策制定的必要性。于是驾驶人状态逐渐成为人机系统多元感知的重要部分,车辆系统实时理解驾驶人的状态有利于制定出更人性化的驾驶人接管策略。其次,随着V2X 技术的发展,如果驾驶人的状态可以被实时检测,那么驾驶人的状态信息可以在车辆周围的局部交通网之间传递共享,相邻车辆和其他道路参与者分别可以根据这些信息调整行车策略和过街策略[3]。这不仅有利于减少交通事故、提高交通效率,还有利于节约能源保护环境。因此,如何实现实时可靠的驾驶人状态检测是一项非常有意义的研究工作。
在驾驶人状态检测中包含驾驶人分心检测、压力检测、疲劳检测、酒驾以及异常驾驶行为检测等。本文的分心驾驶行为检测本质上是检测分心源,属于驾驶分心检测进一步的细分检测。不同的分心行为,如右手操作手机和与乘客交谈,有不同的驾驶绩效,因此在驾驶分心检测的基础上有必要进一步细分分心行为。从广义上讲,驾驶状态检测分为基于驾驶人生理信号(如心电、脑电、皮电)[4-5],驾驶绩效(速度、车辆位置、加速踏板位置和制动踏板位置等)[6-7],眼动数据(眼睛离开道路时长、眨眼频率、视线广度等)[8]和基于图像的检测方法。基于驾驶人生理信号和驾驶绩效的方法虽然在驾驶人状态检测中取得了很好的效果,但在驾驶行为检测中,这两种方法存在一定局限性。不同的分心行为,如左手操作手机和右手操作手机,可能导致相同或相似的驾驶人生理信号和驾驶绩效,因此这两种检测方法可能导致分心行为间的混淆[9]。此外,当驾驶人有大幅度头部或转身动作时,安装在车辆仪表盘附近的传感器很难捕捉到其眼动特征,因此尹智帅等[10]指出基于眼动数据的分心驾驶行为相关研究仍较为欠缺。基于计算机视觉的检测方法主要是通过图像监测驾驶人的头部、面部、手部等部位,然后采用机器学习或深度学习的方法实现图像特征提取进而实现驾驶行为分类。基于计算机视觉的方法是目前最具有前景的分心驾驶行为检测方法[11],本文正是基于计算机视觉方法开展驾驶行为检测研究的。
在基于计算机视觉(computer vision, CV)方法识别分心驾驶行为的研究工作中,广泛应用的深度学习模型为卷积神经网络(convolutional neural networks, CNN)[12-14]。CNN 的主要网络构建包括AlexNet[15]、VGG[16]、Inception[17]、ResNet[18]和Xception[19]。Xing 等[20]将分心驾驶行为分为正常驾驶、检查后视镜、检查左右后视镜、使用车载视频设备、发短信和接听电话7 种类型。首先使用高斯混合模型(GMM)对原始图像进行分割从背景中提取出驾驶人区域,随后使用AlexNet网络预训练的CNN模型对分心驾驶行为进行识别分类,通过这种端对端的分心驾驶行为检测方法实现了7 种分心驾驶行为平均准确率79%的检测。Hssayeni 等[21]证明了在驾驶人行为检测领域深度CNN 比支持向量机有更高的分类精度。尹智帅等[10]通过将驾驶姿态估计网络与ResNet 分类网络融合,建立了基于驾驶人姿态估计的分心驾驶行为检测模型。Zhang 等[22]比较了基于VGG-16 和ResNet-50 预训练模型的驾驶分心模型改进训练的实际效果,最后利用VGG16 网络构建了驾驶分心检测模型。Tran等[23]考虑了包括正常驾驶在内的10 种驾驶行为,评估了基于VGG-16、AlexNet、GoogleNet 和ResNet 4 种网络架构分心驾驶行为检测模型的准确性和实时性。结果表明这4 种模型的分类准确率分别为86%、88%、89%和92%。虽然这些基于CNN 的分心驾驶行为检测方法取得了令人鼓舞的结果,不可否认基于CNN 的模型在常规任务中的优越性,但是CNN 模型内在的缺陷使分心驾驶行为检测模型存在局限性。CNN模型擅长从数据中提取局部特征,但很难捕捉全局特征信息,因此其模型结果可能会过度依赖局部信息,从而导致模型在一定程度上具有不可靠性。
最近,Transformer 算法在自然语言处理领域取得了卓越成绩,研究人员开始尝试将此算法应用于CV领域。Transformer抛弃了传统的CNN建模路线,整个网络结构完全由Attention 机制组成,其核心是多头注意力机制。多头注意力机制能够抽象地理解整个图像不同区域语义元素之间的关系,这就像被打乱的拼图游戏,Transformer 通过图片像素之间关系,依然能够记住它们的组合顺序,可以有效区分不同空间像素的重要性。2020 年,Dosovitskiy 等[24]基于Transformer 算法的位置编码通过将一张224×224的常规图片划分为16×16 的图像块来构建一个Tokens 序列,成功实现了将此算法应用于CV 领域,这种变体的Transformer 算法称为视觉Transformer。ViT 最大程度地继承了Transformer 的原理,能够出色完成图像分类任务[25-26]。Wu 等[27]使用ResNet 作为基准网络来提取低级特征,并将低级特征输入到ViT 模型中转换为视觉Tokens,最终与图像的分类结果相联系。Han 等[28]提出一种嵌套Transformer 结构,其本质上是对第1 层Transformer 结构变换得到的图像块进行第2 次Transformer 变换,以获取图像更加细微的特征。在很多任务中,ViT 模型的绩效已经被证明优于基于CNN 的模型,这表明了全局信息的重要性[29]。然而ViT 并不是完美的,由于ViT算法缺乏提取局部特征的能力,使它很难很好地从背景信息中提取前景信息。现有传统的ViT 模型是通过增加网络参数来提高模型性能,其代价是增加了模型参数量和延长了推理时间[30]。显然,资源受限的车载平台不适合参数量大、推理速度低的模型[31]。
为解决上述问题,本文提出了融合CNN 的局部性、ViT 的全局性和注意力机制的Co-Td-ViT 模型,主要工作是:(1)采用卷积投影代替线性投影将输入图像转换为图像块序列,提高图像块编码的灵活性;
(2)使用深度卷积来提取局部特征,增强相邻Tokens在空间维度上的相关性,通过加入更多局部特征降低模型对编码器深度的依赖,减少模型参数量,提高ViT 的性能和效率;
(3)基于注意力机制理论增加了Tokens 降维模块,并将其放在两个Transformer 编码器块之间,降低Tokens 在Transformer 编码器中传播时的维度,减小模型计算复杂度;
(4)为提高模型的训练性能以及泛化能力,基于迁移学习的思想使用公开数据集对Co-Td-ViT 进行预训练,然后使用实际道路试验数据集对模型进行参数微调,提高模型的泛化能力;
(5)引入基于深度泰勒分解原理分配局部相关性的方法实现了Co-Td-ViT 模型注意力机制的可视化分析,从而解决端到端深度学习模型的“黑箱”问题,增强模型的可解释性;
(6)最后开展真实车辆平台在线验证试验,验证本文所提的分心驾驶行为检测模型的可行性和实用性。
图1 所示为传统ViT 模型结构,由线性变换、位置编码、类别向量嵌入、Transformer 编码器以及分类器组成。线性变换是将图片转换为二维图像块序列。二维特征经过位置编码和类别向量嵌入之后被称为Tokens,其数量和维度影响模型的参数量和计算复杂度。Tokens被送入Transformer编码器中并执行多头注意力机制,Transformer 编码器块的数量同样影响模型参数量。用来分类的向量被称为类别Token,其从Tokens中分离出来进入分类器用于判断图像的类别。

图1 传统ViT结构
图2 示出本文所提出基于ViT 改进的Co-Td-ViT 模型的框架结构。与传统ViT 模型不同,Co-Td-ViT 模型包括了卷积图像块分割、位置编码和类别嵌入、卷积前馈层、Transformer 编码器、Tokens 降维、MLP分类层。下面简单介绍每个模块的功能。

图2 Co-Td-ViT模型结构
(1)卷积图片块分割 为减小Co-Td-ViT 计算消耗,使用卷积投影替换传统的线性投影来获取图像块序列[32]。
(2)位置编码和类别向量嵌入 位置编码的作用是将图片块的位置信息融入特征矩阵中,以增强网络对于不同图像块的位置感以及对于图像不同信息的感知范围;
类别向量嵌入是在特征矩阵中增加一个可学习的类别向量,在模型的最后被提取出来用于识别图像的类别。
(3)卷积前馈层 为减小模型的Transformer 编码器的深度,降低参数量,且让模型更易于训练,本文基于CNN 的平移不变性和局部性提高模型获取底层特征的能力。具体方法是在Transformer编码器之前添加卷积前馈层,改善模型对于底层特征的提取性能。
(4)Transformer 编码器 来自卷积前馈层的特征被送入Transformer 编码器中,并执行多头注意力机制,然后经过层归一化、提取类别Token。值得说明的是本文创新性地提出在Transformer编码器块之间添加了一个基于注意力机制的Tokens 降维模块,从而降低模型的参数量和减小计算复杂度。
(5)Tokens 降维 送入Transformer 编码器中Tokens的维度是影响模型参数量的重要因素。由于驾驶人行为检测区域中包含大量与分心驾驶行为信息无关的特征,所以输入到Transformer 编码器中的部分Tokens 对于分类分心驾驶行为没有实际帮助,且高维Tokens经过多头注意力层和层归一化会产生大量的计算量。为改善这一问题,提高模型对重点Tokens 的关注度,本文基于注意力机制对Tokens 进行降维,在提高模型性能的同时减少参数量。
(6)MLP 分类层 在MLP 层中加入了全连接层FC 和SoftMax,输入类别Token 对分心驾驶行为进行分类。
经过2D 卷积之后的特征维度变为Hi×Wi×C',其中,令Mi=Hi×Wi,然后经过扁平化操作将三维特征转换为二维特征。
式中:GELU 代表激活函数;
BN 代表批量归一化;
Concat代表向量拼接。
如图3 所示,Transformer 编码器由交替的多头自注意力层和多层感知机块(MLP)构成。在每个模块前应用了层归一化,在每个模块后应用残差连接。
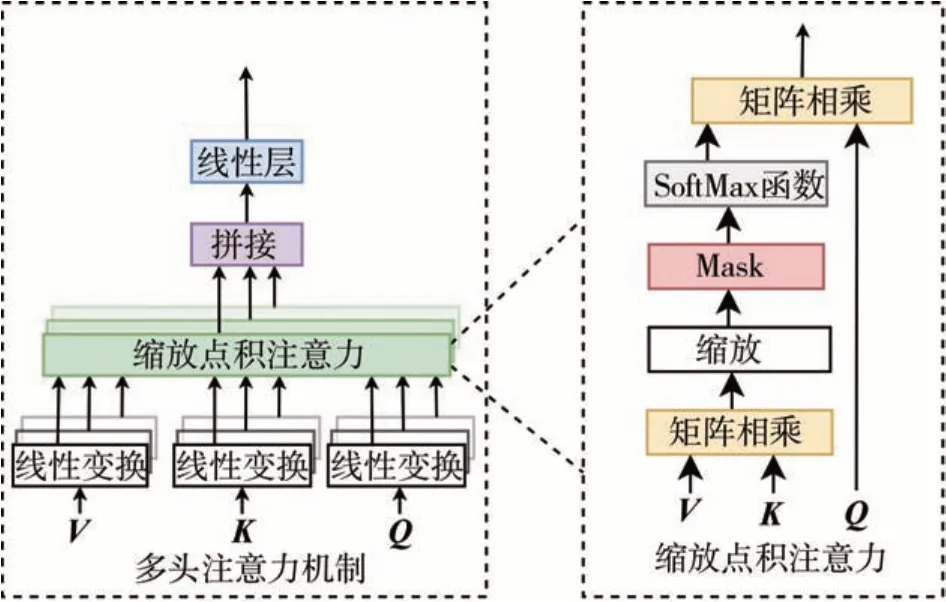
图3 多头注意力机制
多头自注意力将查询、键和值拆分为h个部分,h为多头注意力模块中的头数,每个头的输出值串联并线性投影形成最终输出:
MLP用于非线性特征转换,此过程可以表示为
式中:FC代表全连接层;
W和b分别为全连接层的权重和偏置;
σ(·)代表激活函数。
层归一化是Transformer 结构的关键组成部分,表示为
式中:LN表示层归一化;
x为输入;
μ和δ分别为特征的平均值和标准差;
∘代表向量或矩阵每个元素相乘;
γ和β是可学习的仿射变换参数。
令Transformer 编码器的过程为TE(x),提取类别Token的过程可以表示为
式中:CT 代表从Tokens 中分离出类别Token;
TE 代表Transformer编码器。
基于注意力机制[33],创新性地对Tokens 进行降维。首先引入一个随机生成的可学习的查询向量q∈RN×C',然后执行以下运算:
MLP 分类层包括全连接层FC 和类别分数判别层SoftMax 函数,总类别Tokenxt最终通过MLP 层转换为分心驾驶行为类别分数y:
目前的公开驾驶人行为数据集大都由国外提供,其驾驶人的特征和驾驶习惯与中国人存在一定差异。为进一步弥补基于我国驾驶人行为检测研究的空缺,本研究开展真实驾驶环境下的驾驶人行为数据采集试验。为提高模型的泛化能力,基于迁移学习理论,首先使用大型公开分心驾驶行为数据集对模型进行预训练,然后使用实际道路试验数据集对模型进行参数微调,最终获得符合我国驾驶人驾驶习惯的驾驶员行为检测模型。
2.1.1 公开数据集
使用大型公开分心驾驶行为数据集SFD2[34]和AUCD2[35]对模型进行预训练。每个数据集由真实驾驶场景下所采集的驾驶员分心图片组成,且两种数据集具有相同的分心驾驶行为分类标签,如图4和图5所示。两种数据集将分心驾驶行为划分成10类。合并后的数据集包含不同肤色和体型的被试共70 人,共计36902 帧图像。按照8∶2 的比例将数据集划分为训练集和验证集。

图4 SFD2数据集分心驾驶行为分类

图5 AUCD2数据集分心驾驶行为分类
2.1.2 实际道路试验分心驾驶行为数据集
为获取符合中国人驾驶习惯的分心驾驶行为数据集,本文招募了42 名被试,基于一辆2020 款奥迪A4L 轿车在城市道路开展真实驾驶试验。试验过程中摄像头的安装位置和检测区域如图6所示。

图6 摄像头安装位置与检测区域
结合我国驾驶人的驾驶情况,将分心驾驶行为划分为包括正常驾驶和单手驾驶在内的8 类行为,如图7所示。为验证模型的泛化能力和性能,按照不同驾驶人将数据集划分为训练集、验证集和测试集。其中28名被试的数据用作训练集,7名被试的数据用于模型验证,最后7名被试的数据用于模型测试。

图7 实际道路试验数据集中驾驶人行为分类
试验基于一台配置有Ubantu18.4 系统的服务器进行,基于Python-Pytorch 软件包完成模型代码的编写。CPU 型号为i9-12000k,运行内存为64 GB;
GPU 型号为GTX3090,内存为24 GB。试验分两阶段进行,第1 阶段使用公开数据集对模型进行预训练,第2 阶段使用实际道路试验数据集对模型进行参数微调。在第1 阶段结束时,对预训练模型最后层的神经元个数进行修改,以适应分心驾驶行为类别数量的变化。
各模型及其参数设置如表1 所示。在所有模型中,ViT-2 为传统ViT 模型,其保留了传统ViT 模型的参数设置;
ViT-1 为本文修改的浅层ViT 模型,相比于传统ViT 具有更少的编码器块、多头注意力机制的头数以及MLP 节点个数;
Co-ViT 为ViT-1 基础上增加了卷积优化模块的模型;
Td-ViT 为ViT-1 基础上增加了Tokens 降维模块。在模型参数中,Layer是Transformer 编码器块的数量,FTN 为降维前Tokens 的数量,BTN 为降维后Tokens 的数量,Hidden size 是每个Token 的长度,MLP size 是Transformer 编码器中第一个全连接的节点个数,Heads代表多头注意力模块中头的数量,L1为Tokens降维模块之前的编码器块的数量,L2是Tokens 降维模块之后的编码器块的数量。在预训练阶段,所有模型均执行200 次Epoch,批处理大小为32,使用动量优化方法,动态学习率初始值为0.001。在参数微调阶段中,所有模型的Epoch均设置为30次,批处理大小为32,使用动量优化方法,动态学习率的初始值为0.001。

表1 各模型参数设置
本文所研究的分心驾驶行为检测问题本质上是图像分类问题,为准确评价模型性能,使用深度学习领域常用的交叉熵损失和混淆矩阵评价模型。交叉熵损失用于评价模型训练过程中训练集和验证集的性能,混淆矩阵用于评价模型在测试集上的分类性能。
(1)交叉熵损失
交叉熵损失经常用来衡量深度神经网络输出和标签的差异[36-37],然后利用这种差异反向传播优化模型参数。其主要原理是评价实际输出结果(概率分布)和期望输出(概率分布)的接近程度,两个概率分布越接近,交叉熵值越小,其表达式表示为
式中:p为期望输出概率分布;
q为实际输出概率分布。
(2)混淆矩阵
混淆矩阵是用来总结一个分类器结果的矩阵[38-39],它既可以反映总体的分类精度,又可以反映不同类别各自的分类精度,且可以直观了解正确分类和错误分类的比例。对于n元分类任务,混淆矩阵就是一个n×n的矩阵。对于典型的二元分类任务,常用的评价指标包括准确度Acc,精确度P,召回率R以及F1分数,各评价指标定义如下:
式中:TP为真阳性,代表预测为阳性的样本数量;
TN为真阴性,代表预测为阴性的样本数量;
FP为假阳性,代表预测为阳性的阴性样本数量;
FN为假阴性,代表预测为阴性的阳性样本数量。对于图像多分类问题,常用各指标在各类别下的平均值来评价分类性能,即mAcc、mP、mR以及mF1。
为验证所提模型的优异性能,开展对比试验和消融试验。对比试验中,将Co-Td-ViT 与基于CNN的DenseNet、ResNet-101、EfficientNet、Inception-v4模型以及基于Transformer 的Swin 模型进行对比。在消融试验中,将Co-Td-ViT 与Td-ViT、CoViT、ViT-1、ViT-2 进行对比以验证卷积前馈层和Tokens降维方法的有效性。对比试验和消融试验中所有模型均经过预训练和参数微调两个阶段的训练过程。在分析过程中,首先对比了在参数微调阶段训练集和验证集的损失及精度随迭代次数的变化情况;
然后使用评价参数mAcc、mP、mR、mF1以及混淆矩阵对模型在测试集上的性能进行对比;
最后考虑到车载平台资源的限制性,对比了各模型处理图像的帧率以及参数量,比较哪种模型更适用于车载平台。
3.1.1 对比试验
对比试验结果如图8、图10 和表2~表4 所示。图8 表示各模型在微调阶段训练集和验证集的精度及损失随Epoch 次数的变化情况;
图10 示出各模型的混淆矩阵;
表2 列出了模型的所有评价指标结果;
表3 和表4 分别给出模型的精确度和召回率。总结以上结果可以得出:

表2 不同模型性能对比

表3 各模型P和mP

表4 各模型R和mR

图8 对比试验参数微调过程对比

图9 消融试验参数微调过程对比

图10 各模型的混淆矩阵
(1)Co-Td-ViT 模型在训练集和验证集上的性能都超过了CNN 模型和Swin,训练集的损失和精度分别为0.08 和0.973,验证集损失和精度分别为0.104和0.958。
(2)相比于其它模型,Co-Td-ViT 模型在测试集上的性能最高,其mAcc为96.93%,相比于DenseNet提高了0.62%。同时,模型的P、R以及混淆矩阵显示所提Co-Td-ViT 模型对于每种分心驾驶行为的识别准确度均最高,其mP和mR均为96.95%。此外,各模型对于单手驾驶的识别准确性均较差,Co-Td-ViT 错误识别单手分心驾驶行为的个数为12,低于其它模型。
(3)从表2 可以看出,Co-Td-ViT 模型除具有最高的mAcc、mP、mR、mF1外,还具有更高的推理速度和最小的参数量,相比ResNet-101 参数量减少了21.30 M,推理速度提升了96.56 fps,证明了Co-Td-ViT更适用于分心驾驶行为的实时检测。
3.1.2 消融试验
消融试验结果如图9、图10 和表5~表7 所示,总结以上结果可以得出:

表5 不同模型性能对比

表6 各模型P和mP
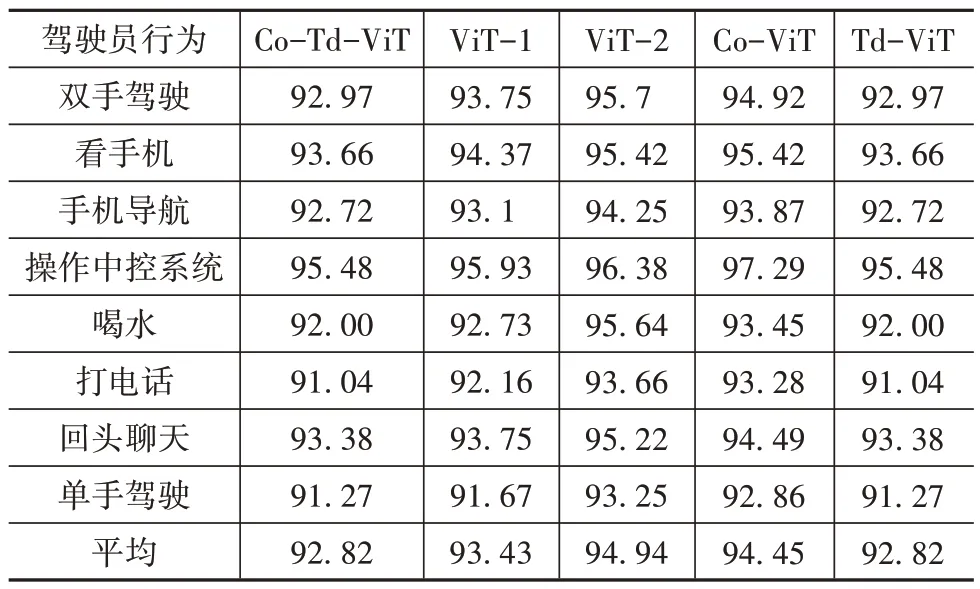
表7 各模型R和mR
(1)相比于Td-ViT 和Co-ViT,Co-Td-ViT 分别增加了卷积前馈层和Tokens 降维模块,虽然参数量相比于CoViT和Td-ViT分别增加了2.43和20.61 M,然而模型的性能改善显而易见。Co-Td-ViT 的训练集损失相比于Co-ViT 和Td-ViT 分别减少了0.017和0.053,训练集的精度分别增加了0.013和0.018。在验证集上同样表现出性能的提升。Co-ViT 相比于ViT-1 训练集和验证集的损失分别减少了0.088和0.083,训练集和验证集的精度分别增加了0.023和0.029,证明提出的卷积优化方法能够帮助模型提高局部特征的提取能力;
Td-ViT 相比于ViT-1 训练集和验证集的损失分别减少了0.025 和0.047,训练集和验证集的精度分别增加了0.008 和0.017,模型的参数量减少了2.45 M,证明提出的Tokens 降维方法能够在降低参数量的同时提高模型的性能。
(2)Co-Td-ViT 同样在测试集上表现出最佳性能,各模型的P、R以及混淆矩阵表明所提Co-Td-ViT 可以降低模型对于每种分心驾驶行为的错误预测的个数。
(3)从表5 可以看出,Co-Td-ViT 模型具有最高的mAcc、mP、mR、mF1,相比于Co-ViT、Td-ViT、ViT-1 和ViT-2,mAcc分别提高了2%、2.53%、4.16%和3.54%。然而由于增加了优化模块,使模型的推理速度有所降低,模型的参数量相比于ViT-1 模型增加了0.32 M,推理速度下降了12.33 fps;
相比于Td-ViT增加了2.77 M,推理速度降低了34.82 fps。
3.2.1 Co-Td-ViT注意力区域分析
如图11 所示,对于双手分心行为,Co-Td-ViT的注意力集中在两只手上,而在驾驶人单手驾驶时,注意力可以准确关注到在转向盘上的右手或左手(图11(h));
当驾驶人使用手机或喝水时,注意力集中在手机或水瓶上(图11(b)、(c)、(e)、(f));
当驾驶人操作中控系统时,注意力集中到中控区域(图11(d));
当驾驶人回头和后排乘客聊天时,注意力更多地集中到了人的脸部(图11(g))。另外,Co-Td-ViT可以区分不同关键信息的重要性,在双手驾驶(图11(a))的样本3 中,注意力准确地聚焦到驾驶员的双手上,没有受到手机的干扰;
在看手机(图11(b))的样本1 中,Co-Td-ViT 的注意力准确地关注到手机位置;
在操控中控系统(图11(d))的样本2 中,注意力没有受亮屏手机的干扰;
在喝水动作(图11(e))的样本2中,注意力集中到手和瓶子相关联的部分,没有受储物格中水瓶的干扰。由此可见Co-Td-ViT 的注意力机制能够有效区分不同像素区域的重要性。

图11 Co-Td-ViT注意力区域在试验数据集上的可视化
3.2.2 各模型注意力区域对比分析
为解析模型识别结果,将不同模型的注意力区域进行对比。首先随机抽取每种驾驶行为中的一张图片(图12(a)),并输入到模型中,然后对每个模型的注意力区域进行可视化分析。试验结果如图12所示。得益于多头注意力机制以及ViT 模型表达全局信息的能力,所提的Co-Td-ViT 模型(图12(b))的注意力能够完全捕捉驾驶人的行为特征,且关注的区域相对更加集中和精细。对比CNN 模型(图12(c)~图12(f)),虽然也能够捕捉到主要特征,但注意力比较分散,例如图12(d)样本1,图12(e)样本3、4、7,图12(f)样本4、7,且存在注意力分配错误的现象(图12(c)样本7、8,图12(d)样本7,图12(e)样本7、8,图12(f)样本4、7、8)。Swin 模型的注意力区域相对集中,但注意力分配错误的情况较多(图12(g)样本1、7、8),综上,所提Co-Td-ViT 模型特征识别和提取能力相比于对比的CNN 模型和Swin 模型更强。

图12 各模型注意力区域可视化
为验证本文提出的Co-Td-ViT 模型的实时推理性能,基于实车平台进行在线分心驾驶行为识别。硬件平台为一台GPU 型号为GTX 1050ti 的笔记本电脑。试验中要求被试在一段时间内完成用手机导航、操作中控以及看手机的动作。试验结果如图13所示,图中不同颜色的曲线代表不同分心驾驶行为的识别概率随图像帧数的变化情况。可以看出Co-Td-ViT 能够准确识别每种动作,且每种动作的识别概率变化较为平稳,在两种动作之间概率值波动较大,这可能是因为在动作切换的过程中包含了没有训练到的动作类型,从而导致了识别错误。试验中得到模型的在线推理速度为23.32 fps,能够满足实时性检测的要求。因此,Co-Td-ViT 模型能够实时地、高精度地识别分心驾驶行为。

图13 分心驾驶行为识别概率曲线
以分心驾驶行为检测为出发点,引入ViT 算法,提出了一种基于深度卷积与Tokens 降维的ViT 模型用于分心驾驶行为实时检测,改善了ViT 算法不善于捕捉局部特征和模型参数量较大的问题。基于CNN 的平移不变性和局部性特点,在Transformer 编码器之前添加卷积前馈层,以此来增强模型对底层特征的获取能力;
首次在Transformer 编码器块之间添加了基于注意力机制的Tokens 降维模块,提高了模型对重点Tokens 的关注度,在改善模型性能的同时减少了模型的参数量。基于迁移学习的思想,通过预训练和参数微调两阶段的模型训练过程提高了模型的泛化性能。通过与现有模型的对比试验、消融试验以及模型注意力区域可视化分析,对Co-Td-ViT模型进行了验证。
对比试验结果表明:Co-Td-ViT 相比于CNN 模型和传统ViT 模型具有性能优势,通过对比模型参数量和推理速度证明了Co-Td-ViT 模型具有较强的实时检测性能。消融试验结果表明:所提的卷积优化方法和Tokens 降维方法是有效的。此外,通过注意力区域的可视化分析探究了端到端“黑箱”模型的注意力机制,Co-Td-ViT 模型能够区分不同像素区域的重要性,相比于CNN 模型能将更多注意力集中到驾驶人的动作关键信息上。最后,基于真实车辆平台在线验证的结果表明所提的Co-Td-ViT 模型能够准确实时地检测驾驶人行为。
猜你喜欢降维编码器注意力混动成为降维打击的实力 东风风神皓极车主之友(2022年4期)2022-08-27让注意力“飞”回来小雪花·成长指南(2022年1期)2022-04-09降维打击海峡姐妹(2019年12期)2020-01-14基于FPGA的同步机轴角编码器成都信息工程大学学报(2018年3期)2018-08-29“扬眼”APP:让注意力“变现”传媒评论(2017年3期)2017-06-13基于PRBS检测的8B/IOB编码器设计电子设计工程(2017年20期)2017-02-10A Beautiful Way Of Looking At Things第二课堂(课外活动版)(2016年2期)2016-10-21JESD204B接口协议中的8B10B编码器设计电子器件(2015年5期)2015-12-29多总线式光电编码器的设计与应用电测与仪表(2014年13期)2014-04-04抛物化Navier-Stokes方程的降维仿真模型计算物理(2014年1期)2014-03-11扩展阅读文章
推荐阅读文章
推荐内容
明翰范文网 www.tealighting.com
Copyright © 2016-2024 . 明翰范文网 版权所有
Powered by 明翰范文网 © All Rights Reserved. 备案号:浙ICP备16031184号-2